SWE-Pruner:程式碼智能體之自適應上下文修剪機制與理論深度分析報告
https://arxiv.org/abs/2601.16746
執行摘要與前瞻視野
在當代軟體工程的演進歷程中,大型語言模型(Large Language Models, LLMs)的應用已經跨越了單純的程式碼片段補全與靜態語義分析,正式邁入能夠自主導航龐大程式碼庫、執行複雜測試指令並端到端提交修補程式的互動式智能體(Coding Agents)時代 。諸如 Claude Code 與 Gemini CLI 等先進工具鏈的問世,賦予了模型操作終端機與檔案系統的權限,使其具備了執行多步邏輯推理的潛力 。然而,隨著智能體處理真實世界軟體專案複雜度的指數級提升,其效能無可避免地撞上了一堵被稱為「上下文之牆」(Context Wall)的物理與認知邊界 。
在長程、多輪的軟體除錯與開發互動中,不斷累積的歷史上下文不僅帶來了高昂的應用程式介面(API)呼叫成本與極高的運算延遲,更引入了海量的語義雜訊 。這些雜訊導致模型產生嚴重的注意力稀釋(Attention Dilution)與幻覺現象(Hallucinations),使得智能體在關鍵決策節點迷失方向 。傳統的上下文壓縮技術多數針對自然語言的機率分佈設計,依賴困惑度(Perplexity)等靜態且任務不可知的指標進行詞塊(Token)級別的無差別修剪 。將這些方法強行應用於具備嚴格抽象語法樹(AST)的程式碼時,往往會引發災難性的後果,不僅破壞了程式語言嚴謹的句法結構,更經常丟失除錯過程中至關重要的字元級實作細節 。
為徹底突破此一理論與實務瓶頸,本報告深入解析一種專為程式碼智能體量身打造的自適應上下文修剪框架——SWE-Pruner 。該框架的設計哲學深刻汲取了人類資深工程師在開發與除錯時的「選擇性略讀」(Selective Skimming)認知行為模式 。SWE-Pruner 允許智能體在每輪環境互動中,基於當下的推理狀態動態生成明確的「目標提示」(Goal Hint,例如指示系統「專注於 MRO 解析邏輯」),並透過一個僅有 0.6B 參數的輕量級神經網絡(Neural Skimmer),在嚴格保持程式碼行級(Line-level)結構完整性的前提下,精準篩選出與目標高度相關的上下文片段 。
詳盡的實證數據表明,SWE-Pruner 在嚴苛的多輪互動基準測試(如 SWE-Bench Verified)中,能為 Claude Sonnet 4.5 及 GLM 4.6 等業界頂尖模型減少 23% 至 54% 的絕對詞塊消耗,同時逆勢提升高達 1.4 個百分點的任務成功率,並減少最多 26% 的無效互動輪數 。在 LongCodeQA 等單輪長上下文問答任務中,該框架更實現了高達 14.84 倍的驚人壓縮率,且對核心效能的影響微乎其微 。此一突破性進展,不僅大幅降低了 AI 輔助軟體工程的營運成本,更為構建具備長效記憶與高認知專注力的自主智能系統奠定了關鍵的架構基礎。
理論背景與上下文危機的實證分析
程式碼智能體的認知負荷與成本結構解構
在真實世界的企業級軟體開發場景中,程式碼智能體通常被投放於一個完全陌生且體積龐大的程式碼庫中。為了建立對系統全域架構的理解並精確定位潛在的軟體缺陷,智能體必須採用粗粒度的檔案操作工具(如 grep, cat, head 等)進行廣泛且反覆的探索 。這種探索策略雖然在邏輯上對於建立全域認知至關重要,但其物理代價是會將成千上萬行的原始檔案或日誌串流,毫無保留地載入語言模型的上下文視窗中 。
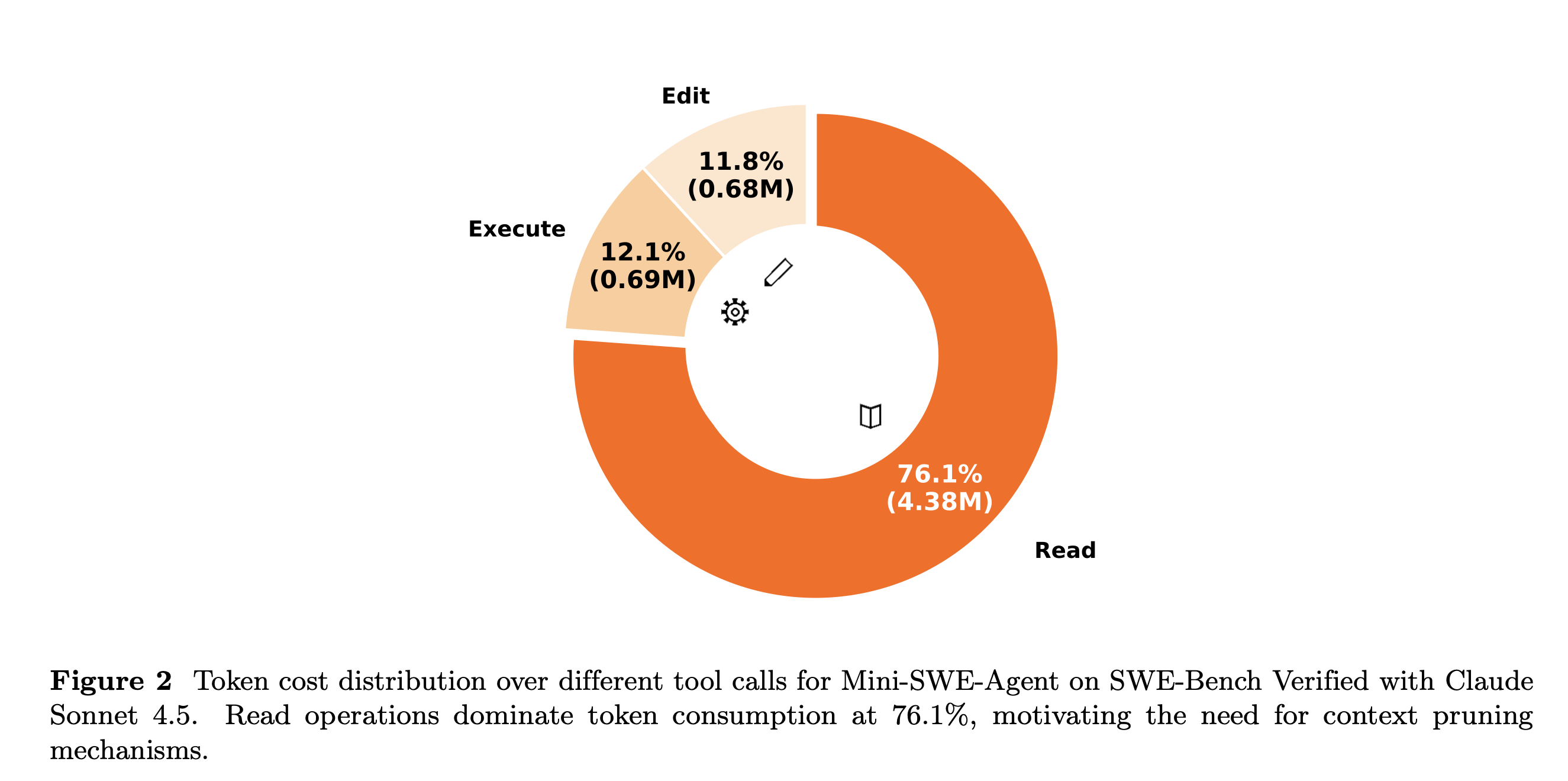
為了量化這種行為模式帶來的資源消耗,研究團隊對 Mini-SWE-Agent 代理框架在 SWE-Bench Verified 基準測試上的互動軌跡進行了深度的實證分析 。該分析以 Claude Sonnet 4.5 為驅動核心,將智能體的所有工具呼叫行為嚴格分類為三大類型:讀取操作(涵蓋檔案與目錄的檢索檢視)、執行操作(涵蓋編譯與測試腳本的運行)以及編輯操作(涵蓋程式碼的就地修改) 。
分析結果揭示了一個極端不平衡且令人震驚的詞塊預算分配結構。數據表明,讀取類型的操作佔據了絕對的統治地位,消耗了高達 76.1% 的總詞塊(絕對數量約為 4.38M tokens) 。相較之下,真正推進任務進度的執行操作僅佔 12.1%(約 0.69M tokens),而直接修復問題的編輯操作佔比更低至 11.8%(約 0.68M tokens) 。
為驗證此一現象是否受到特定模型架構的偏差影響,研究團隊將相同的軌跡追蹤方法應用於架構與訓練範式截然不同的開源模型 GLM-4.6 上 。實驗數據呈現出高度一致的物理規律:GLM-4.6 的讀取操作同樣主導了詞塊消耗,佔比高達 67.5%(約 2.89M tokens),而編輯與執行操作則分別佔據 18.5% 與 14.0% 。
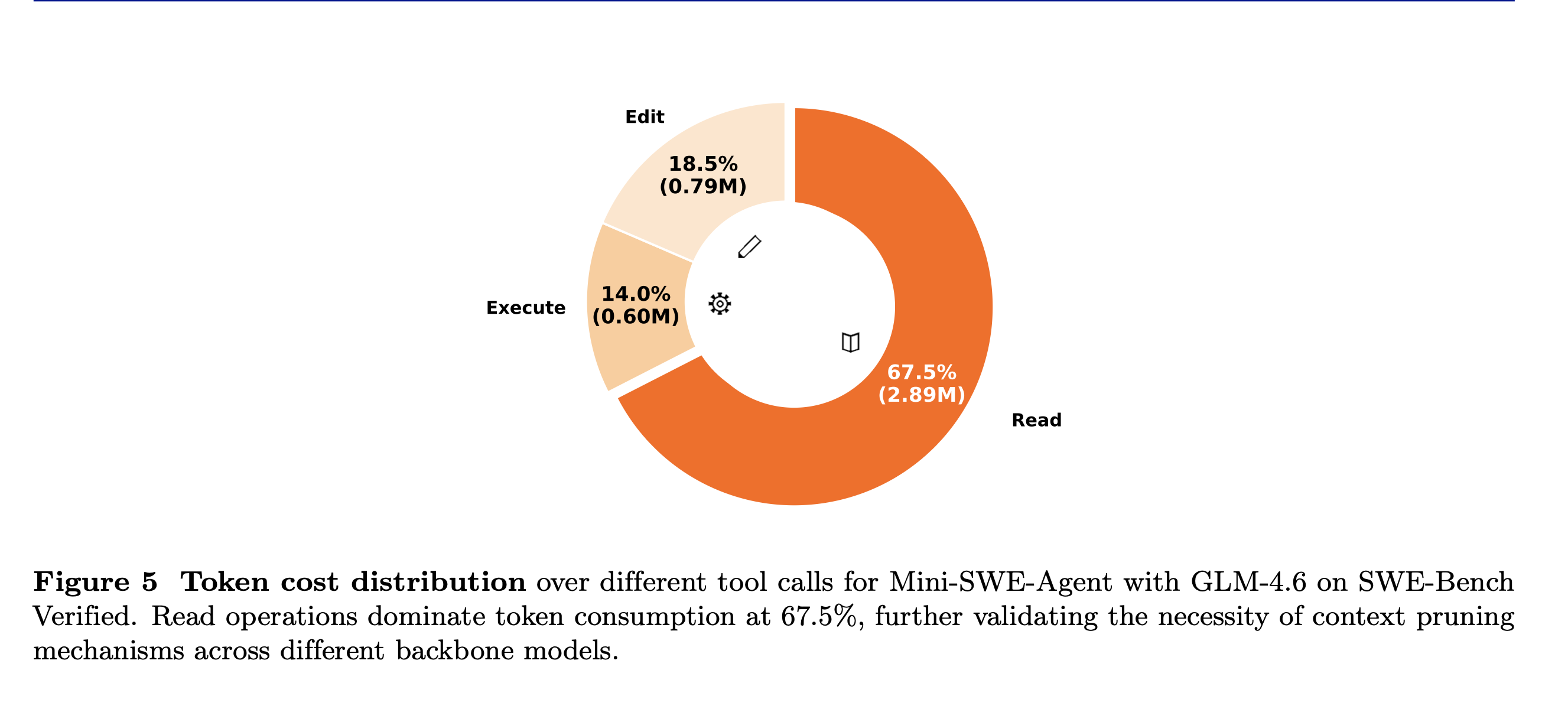
這種跨越模型架構的驚人一致性,深刻揭示了程式碼智能體運作機制中的一個根本性缺陷:智能體絕大部分的算力、金錢成本與上下文空間,都不可避免地浪費在處理探索階段所引入的冗餘環境觀察中 。隨著多輪互動的持續推進,早期檢索到但後續不再需要的非關鍵程式碼,會在其歷史紀錄中不斷堆疊。這種「上下文累積效應」不僅拖垮了系統的反應速度,更讓模型在龐雜的程式碼迷宮中逐漸喪失對核心問題的推理聚焦能力 。
傳統壓縮策略在程式碼領域的結構性失效
面對日益嚴峻的上下文過載危機,學界與業界曾提出多種試圖緩解該問題的壓縮方案。然而,當這些源自自然語言處理(NLP)領域的技術被強行移植到具有高度形式化特徵的軟體工程領域時,皆顯露出致命的理論與應用缺陷 。
第一類主流方法為詞塊級的靜態修剪技術(Token-level Pruning),其代表性框架包括 Selective-Context 與 LLMLingua2 。這類方法的核心運作邏輯是基於資訊理論中的自信息量(Self-information)或語言模型計算出的困惑度,將機率較高、看似「可預測」的詞塊視為低資訊量冗餘並予以刪除 。然而,程式碼與自然語言有著本質的差異,程式碼依賴嚴格的抽象語法樹(AST)來維持邏輯運算。以詞塊為單位的隨機刪除,會輕易且不可逆地破壞變數宣告的完整性、控制流的縮排範圍以及函式區塊的括號匹配 。實證數據無情地指出,經過 LLMLingua2 壓縮後的程式碼,其 AST 正確性僅存 0.29%,這意味著壓縮後的文本在編譯器或語言模型眼中,已退化為毫無語法意義的字元碎片 。
第二類方法為粗粒度檢索(Coarse-grained Retrieval)與生成式摘要(Generative Summarization) 。檢索增強生成(RAG)透過將程式碼切分為函式區塊並計算嵌入向量相似度來提取內容。儘管這保留了局部的語法完整性,但在複雜的除錯任務中,一個導致系統崩潰的關鍵異常處理邏輯可能僅隱藏在某一兩行程式碼中,粗粒度的向量比對極易將這些微小但致命的細節判定為低相關性而予以遺漏 。另一方面,使用大型語言模型(如 LLM Summarize)對程式碼檔案生成抽象摘要,雖然能有效提取模組的大意,卻會徹底抹除字元級別的實作資訊,剝奪了智能體進行精確代碼編輯的基礎,同時摘要生成的過程本身也引入了令人難以接受的高昂延遲 。
第三類方法則聚焦於智能體歷史軌跡的管理(Agent History Compression),如 SUPO、COMPASS 或 Agent Fold 等框架 。這些技術透過強化學習或主動折疊策略來壓縮智能體過去的對話與反思紀錄。儘管這些方法有效控制了對話輪次的增長,但它們完全迴避了「環境觀察(即檔案內容)本身過於龐大」的根本問題,因此無法真正解決因讀取大型檔案所造成的即時上下文溢位 。
綜上所述,一個真正適用於程式碼智能體的理想壓縮機制,必須同時滿足三個嚴苛的條件:其一,必須是動態且具備任務感知能力(Task-aware),能夠隨著智能體不斷變化的推理目標調整過濾標準;其二,必須是結構保留的(Structure-preserving),絕對不能破壞程式碼的語法有效性;其三,必須具備極致的輕量化特徵(Lightweight),以確保壓縮過程不會成為系統新的效能瓶頸 。這三大理論訴求,正是孕育 SWE-Pruner 架構設計的核心基石。
SWE-Pruner 系統架構與數學機制深度剖析
為了解決上述理論衝突與技術瓶頸,研究團隊提出了 SWE-Pruner,這是一個運作於程式碼智能體與其執行環境之間的中介軟體(Middleware)框架 。當智能體透過終端機發出讀取檔案的系統指令時,SWE-Pruner 會主動攔截可能包含數千行原始碼的龐大上下文 。系統不會直接將這些充滿雜訊的資料灌入智能體的記憶體,而是要求智能體提供一個描述當下意圖的「目標提示」,接著透過輕量級神經網絡進行精準過濾,最終僅放行高度相關且語法完整的程式碼行 。
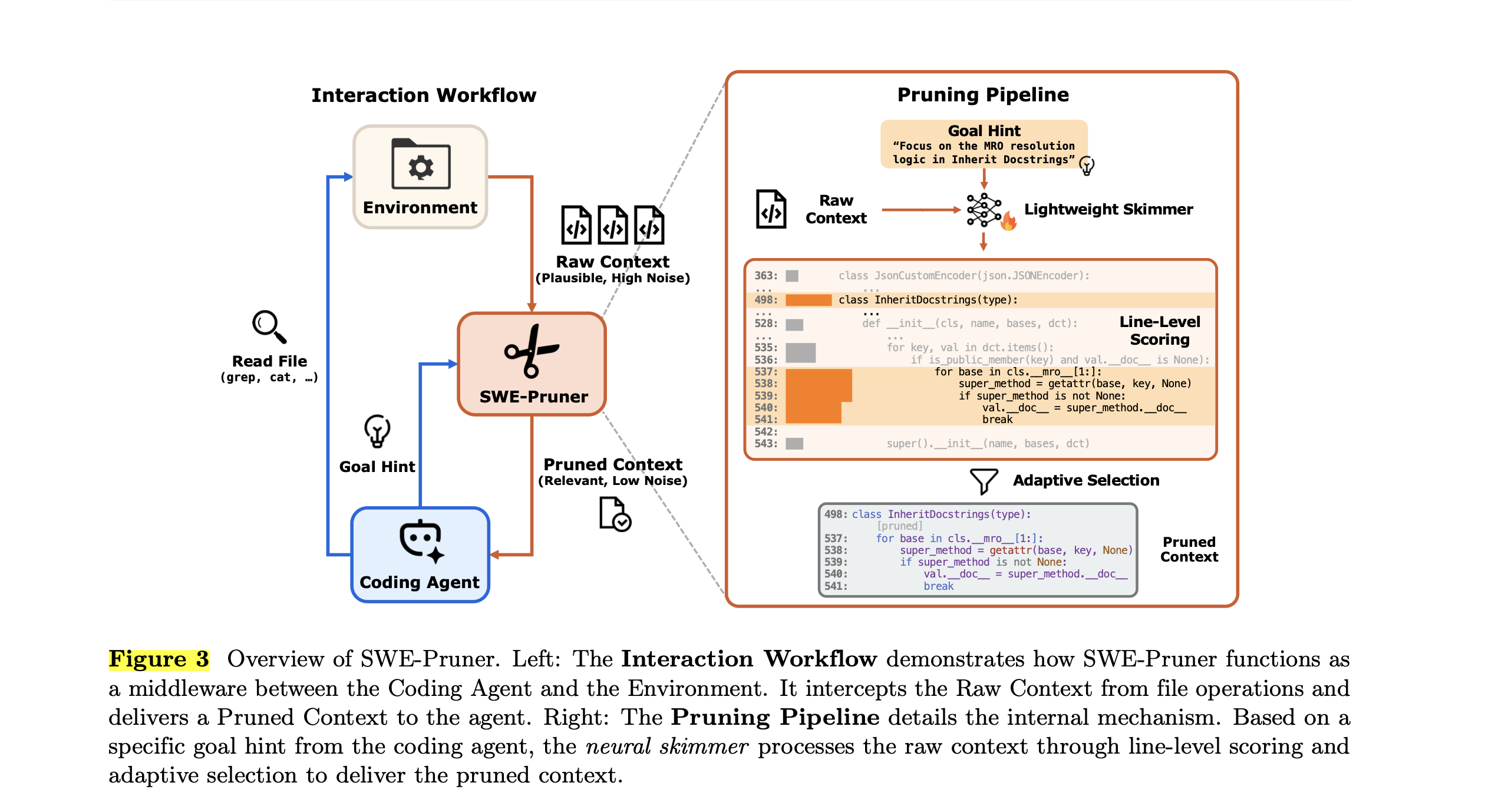
意圖驅動的目標提示生成機制
SWE-Pruner 運作的第一步,在於精確捕捉智能體當下的認知需求。與傳統依賴死板關鍵字比對的過濾系統不同,SWE-Pruner 透過精密的提示詞工程(Prompt Engineering),引導目標智能體將其內部推理狀態轉化為結構化的自然語言問句 。
在具體實作上,系統對標準的 Unix 檔案操作工具(如 cat, grep)進行了無侵入式的封裝,為這些工具新增了一個名為 context_focus_question 的可選參數 。智能體被指示,當預期指令輸出可能過大時,應提供一個完整且自包含的問題(例如:「系統如何確保並行寫入時的資料一致性?」),以此作為引導過濾器的語義信號 。當此參數被賦值時,擷取到的原始輸出與該問題將一同被送入神經略讀器進行裁切;若智能體判定需要檢視完整結構而省略此參數,系統則會優雅地降級為原始行為,直接回傳未經修改的完整內容 。這種極具彈性的輕量級包裝設計,確保了 SWE-Pruner 能夠在不破壞現有智能體工作流程的前提下,實現平滑的向下相容與系統整合 。
輕量級神經略讀器之雙頭架構設計
系統的心臟是一個參數規模僅 0.6B 的神經略讀器(Neural Skimmer),其底層採用 Qwen3-Reranker-0.6B 作為特徵提取骨幹,並進行了深度架構改造,擴充為包含「修剪頭」(Pruning Head)與「重排頭」(Reranking Head)的雙任務學習網絡 。
為了讓如此小巧的模型能夠理解深層的程式碼語義,系統實作了多層特徵融合(Multi-Layer Feature Fusion)機制 。模型不僅依賴最終層的輸出,更主動提取並串聯了骨幹網絡中第 7、14 與 28 層的隱藏狀態。這些跨越不同語義深度的特徵融合後,會依序通過一個自注意力區塊與一個具有 8 個注意力頭、隱藏層維度為 256 的多頭注意力層進行精煉,從而賦予模型極其敏銳的上下文洞察力 。
詞塊到行級的聚合演算法
在評估階段,模型將上下文修剪定義為一個條件排序問題。給定智能體接收到的原始上下文序列與查詢目標,模型首先透過神經網絡參數計算每個單一詞塊的局部相關性分數 。
s_=\mathcal{F}(q,x_{i}|C;\theta)
公式中,分數計算不僅考量了查詢條件與當前詞塊,更將整個上下文的宏觀狀態納入條件機率的評估中 。然而,直接依賴詞塊分數進行修剪正是導致 LLMLingua 等前人工作失敗的主因。為跨越這道鴻溝,SWE-Pruner 導入了行級聚合(Line-level Aggregation)邏輯。系統將連續的上下文拆解為以「行」為單位的集合,並計算每一行所包含之所有詞塊分數的算術平均值,以此作為該行的最終保留指標 。
\overline{s}_{j}=\frac{1}{|T_{j}|}\sum_{t \in T_{j}}s_{t}
這項平均化操作具備深遠的物理意義:它確保了程式碼行是基於其整體的語義連貫性被系統評估,有效避免了因單一關鍵字得分過高而導致模型過度保留無意義的碎片代碼,是維持後續智能體閱讀體驗流暢度的數學基礎 。
條件隨機場(CRF)與聯合優化目標
在訓練過程中,為賦予模型對程式碼結構的先驗感知能力,修剪頭捨棄了傳統的二元交叉熵(BCE)分類,轉而採用條件隨機場的負對數似然(CRF-NLL)作為核心優化目標 。CRF 的卓越之處在於它將每一行的保留與否視為一個連續的序列標註問題,顯式地建立了相鄰決策之間的轉移機率模型 。
給定特徵表示與目標標籤序列,CRF 的得分函數精妙地結合了由局部特徵決定的發射電位(Emissions)與捕捉行際依賴的轉移電位(Transitions) 。
score(x,y)=start_{y_{1}}+\sum_{t=1}^{T}emissions_{t,y_{t}}+\sum_{t=2}^{T}transitions_{y_{t},y_{t-1}}+end_{y_{T}}
透過配分函數進行全域指數正規化後,模型得以學習到諸如「如果 if 條件式被保留,則對應的 else 區塊及閉合括號也應傾向於被保留」的高階結構邏輯 。
\log Z(x)=\log\sum_{y^{\prime} \in \mathcal{Y}^{\prime}}\exp(score(x,y^{\prime}))
在損失函數的設計上,系統採用了序列長度正規化來抑制模型在處理超長上下文時過度激進的修剪傾向 。
\mathcal{L}_{compress}=\frac{1}{B}\sum_{i=1}^{B}\frac{\mathcal{L}_{CRF-NLL}(x_{i},y_{i})}{L_{i}}
最終的優化目標結合了修剪損失與維持模型文件級評分能力的重排損失(均方誤差),並透過權重參數(設定為 0.05)進行精準平衡,確保輕量級模型在獲得行級精剪能力的同時,不喪失全域的檢索直覺 。
\mathcal{L}_{total}=(1-\lambda)\cdot\mathcal{L}_{compress}+\lambda\cdot\mathcal{L}_{rerank}
多維度訓練範式與高品質多語種資料集構建
要訓練出具備強大結構感知與任務導向能力的 CRF 神經略讀器,高品質且包含行級標註的監督資料是不可或缺的。然而,縱觀開源社群與學術界,皆不存在滿足此一嚴苛要求的現成資料集 。為此,研究團隊設計並實作了一套基於「教師-學生範式」(Teacher-Student Paradigm)的合成資料庫構建管線 。
程式碼源的甄選與正規化
資料構建的基石來自於 GitHub Code 2025 數據集,這是一個包含超過 150 萬個優質儲存庫的龐大語料庫 。研究團隊從中精心抽樣了 5,945 個活躍專案中的 195,370 個源代碼檔案 。為確保資料的純淨度,所有被選中的檔案都經歷了極其嚴苛的預處理與正規化流程,徹底剔除了二進位構建產物、自動生成的配置雜訊以及經過混淆壓縮的微型代碼(Minified Code) 。這一過程確保了留存下來的資料,皆是具有高度語義價值且跨越多種程式語言範式(Polyglot)的原始結構,為後續訓練提供了卓越的泛化基礎 。
涵蓋完整生命週期的智能體任務分類學
為了讓神經略讀器能夠從容應對真實世界中千變萬化的智能體開發情境,研究團隊建構了一套包含九大維度的「智能體任務分類學」(Agentic Task Taxonomy),以此引導教師模型生成高度擬真的自然語言查詢 。這九大任務精確映射了軟體工程師在日常開發中的認知軌跡:
這九個維度分別為:程式碼摘要(模擬系統整合前的高階模組審查)、重構建議(聚焦於提升演算法的空間複雜度或架構模組化程度)、相關片段定位(要求模型在茫茫代碼海中精確指出特定業務邏輯的實作點)、程式碼優化(尋求效能瓶頸的突破)、程式碼定位(針對錯誤日誌或崩潰報告尋找發源地)、原理解釋(探討特定設計模式或數學公式的運用動機)、程式碼除錯(尋求針對邊緣案例異常的具體修復方針)、特徵添加(在不破壞現有狀態機的前提下無縫擴充新功能),以及特殊的程式碼補全任務(以代碼片段本身作為查詢,模擬即時開發環境中的上下文感知補全) 。透過強制在這些多元任務上進行訓練,模型學會了根據不同意圖動態調整修剪的寬容度與聚焦深度。
大模型作為裁判(LLM-as-a-Judge)之極致品質過濾
在生成階段,團隊動用了具有 300 億參數的 Qwen3-Coder-30B-A3B-Instruct 作為教師模型,負責基於原始碼與任務分類生成對應的查詢及行級二元遮罩(Binary Line-level Mask) 。然而,機器生成的行級標註不可避免地會出現過度修剪或邏輯斷層的瑕疵。
為確保黃金標準的資料品質,管線引入了具有 800 億參數且具備深度推理能力的 Qwen3-Next-80B-A3B-Thinking 作為終極裁判(Judge) 。該裁判模型被賦予了嚴格的評估準則,從三個正交維度對每一筆合成資料進行嚴格審查:第一是「查詢品質」,拒絕任何語意模糊或缺乏具體開發意圖的問題;第二是「刪除關聯性」,檢驗被標記為刪除的程式碼是否確實為無關雜訊;第三,也是最核心的「語義留存度」,嚴厲把關剩餘的代碼區塊是否依然維持句法正確與邏輯可讀 。
經過這套猶如煉油廠般嚴密的過濾機制,僅有約六分之一的候選樣本通過考驗。團隊最終提煉出 61,184 筆具有精實驗證行級標註的高品質訓練四元組 。這些數據的平均查詢長度達到 39.98 個詞彙,完美捕捉了真實開發者在複雜除錯場景中細膩且具體的資訊訴求,為神經略讀器的卓越表現注入了靈魂 。
多輪智能體任務的效能評估與實證突破
SWE-Pruner 的真正價值,必須在最貼近真實軟體開發流程的動態環境中接受檢驗。為此,研究團隊在涵蓋多輪互動場景的旗艦級基準測試上展開了詳盡的評估。
SWE-Bench Verified:效率與成功率的雙重躍升
在評估多輪除錯能力的 SWE-Bench Verified 測試中(包含 500 個真實世界 GitHub Issue 的端到端修復),系統被無縫整合至 Mini SWE Agent 框架中,並分別以 Claude Sonnet 4.5 及 GLM-4.6 作為心智引擎進行雙盲測試 。
實驗結果呈現了令人振奮的雙軌突破。對於 Claude Sonnet 4.5 而言,引入 SWE-Pruner 後,平均每個任務實例的詞塊消耗從 0.911M 銳減至 0.701M(降低 23.1%),更令人驚豔的是,其任務解決率不僅沒有因為資訊減少而衰退,反而逆勢從 70.6% 提升至 72.0% 。而在 GLM-4.6 模型的表現上,這種「少即是多」的效應更加猛烈:詞塊消耗狂降 38.3%(從 0.791M 降至 0.488M),任務成功率從 55.4% 攀升至 56.6%,同時智能體的平均互動輪數大幅縮減了 25.7%(從 49.3 輪下降至 36.6 輪) 。
| 智能體與模型配置 | 互動輪數 | 成功率 (%) | 總詞塊消耗 (M) | API 預估成本 ($) |
|---|---|---|---|---|
| Mini SWE Agent (Claude 4.5) | 51.0 | 70.6 | 0.911 | 0.504 |
| + SWE-Pruner (Claude 4.5) | 41.7 (-18.2%) | 72.0 (+1.4%) | 0.701 (-23.1%) | 0.369 (-26.8%) |
| Mini SWE Agent (GLM 4.6) | 49.3 | 55.4 | 0.791 | 0.055 |
| + SWE-Pruner (GLM 4.6) | 36.6 (-25.7%) | 56.6 (+1.2%) | 0.488 (-38.3%) | 0.035 (-36.4%) |
這組數據揭示了一個深刻的認知科學洞察:在程式碼推理任務中,上下文壓縮不單單是為了「節省運算成本」的妥協手段,它實質上是一種「強化認知專注力」的主動機制 。透過神經略讀器前置過濾掉冗餘的探索雜訊,底層語言模型不再被無關的邏輯分支所迷惑,因而能夠展現出更果斷的推理直覺,直接減少了無效的反覆讀取操作,進而促成了整體互動輪次與成本的斷崖式下降 。
壓縮策略的橫向切片對比分析
為了進一步驗證「為何」是 SWE-Pruner 取得最佳表現,研究團隊在 SWE-Bench 的隨機 50 個樣本子集上,針對目前主流的上下文管理策略進行了橫向對比實證 。
| 上下文管理策略 | 平均輪數 | 任務成功率 (%) | 詞塊總消耗 (M) |
|---|---|---|---|
| 無壓縮基準 (Mini SWE Agent) | 52.3 | 62.0 | 0.972 |
| + LLMLingua2 (詞塊級修剪) | 42.1 | 54.0 | 0.856 |
| + RAG (粗粒度段落檢索) | 40.2 | 50.0 | 0.771 |
| + LLM Summarize (生成式摘要) | 41.3 | 56.0 | 0.794 |
| + LongCodeZip (語法結構壓縮) | 44.3 | 54.0 | 0.889 |
| + SWE-Pruner (任務感知行級修剪) | 41.1 | 64.0 | 0.670 |
對比數據無情地暴露了傳統壓縮理論在軟體工程領域的死穴。LLMLingua2 與 RAG 雖然表面上達成了降低輪數與詞塊的目的,但代價是任務成功率從 62.0% 崩盤至 54.0% 與 50.0% 。這印證了先前的理論假設:詞塊級修剪撕裂了代碼的語法完整性,導致模型產生編譯幻覺;而 RAG 的粗粒度檢索則無可避免地漏掉了關鍵的實作微觀細節 。唯有 SWE-Pruner 成功在「結構保存」與「雜訊過濾」之間找到了完美的帕雷托最佳解(Pareto Optimum),以最低的資源消耗(0.670M)斬獲了全場最高的成功率(64.0%) 。
而在針對程式碼問答的 SWE-QA 測試中,SWE-Pruner 搭載於 OpenHands 框架上,橫跨 Streamlink、Reflex 與 Conan 等三大相異生態的儲存庫,同樣取得了 29% 至 54% 的驚人詞塊縮減,且模型在 LLM-as-a-Judge 的五維度品質評分上未見任何明顯衰退,再次證實了該架構極強的泛化生存能力 。
單輪理解任務下的極限壓縮邊界探索
儘管 SWE-Pruner 的誕生是為了解決多輪智能體的互動瓶頸,但其核心的目標感知與行級過濾機制,在處理傳統的單輪長上下文理解任務時,同樣展現出了降維打擊般的統治力 。研究團隊選擇了 Long Code QA(應對長達 100 萬詞塊的超大代碼庫問答)與 Long Code Completion 兩項極端基準,並設定了 4 倍與 8 倍的嚴格壓縮約束條件進行壓力測試 。
在使用 Qwen2.5-Coder-7B-Instruct 進行評估的 8 倍壓縮極端環境下,SWE-Pruner 的表現令人矚目: 在 Long Code QA 任務中,當多數基線模型因上下文坍縮而導致準確率大跌時,SWE-Pruner 憑藉精準的目標鎖定,實際達成了 14.84 倍的超高壓縮率,並將準確率死守在 58.71% 的高位。作為強烈對比,依賴純量檢索的 RAG 方法僅能勉強維持 55.86%(且壓縮率不足 7 倍),而強調結構壓縮的 LongCodeZip 準確率更跌至 54.95% 。 在 Long Code Completion 任務中,SWE-Pruner 在 10.92 倍的實際壓縮比下,依舊取得了 57.58 的編輯相似度(ES)與 31.0 的精確匹配率(EM)。反觀基於資訊熵的 Selective-Context 方法,其 ES 分數在此約束下直接雪崩至 48.67,宣告了該方法在長代碼場景下的實用性破產 。
| 測試任務 | 壓縮約束 | 指標 | Selective-Context | LLMLingua2 | RAG | LongCodeZip | SWE-Pruner |
|---|---|---|---|---|---|---|---|
| Long Code Completion | 4x | 有效壓縮率 | 3.27x | 3.32x | 3.29x | 2.77x | 5.56x |
| ES / EM | 52.48 / 22.0 | 49.47 / 15.5 | 58.97 / 30.5 | 57.77 / 28.0 | 58.63 / 31.5 | ||
| Long Code QA | 8x | 有效壓縮率 | 3.69x | 3.57x | 3.06x | 3.98x | 14.84x |
| 準確率 (Acc) | 55.36% | 51.79% | 55.86% | 54.95% | 58.71% |
為了進一步確認此現象並非 Qwen 模型家族的特異功能,團隊更換為架構不同的 Seed-Coder-8B-Instruct 進行交叉驗證 。數據顯示,SWE-Pruner 在 8 倍約束的 Long Code QA 任務中依然斬獲 14.68 倍壓縮與 55.75% 的最高準確率,遙遙領先群雄。這項獨立驗證堅實地證明了:結合任務感知與行級保留的修剪範式,是一種跨越模型底層架構的通用型普適真理 。
系統效率與句法結構保留的底層機制解密
任何被標榜為「中介軟體」的增強模組,若其自身引入的運算開銷超過了其節省的成本,便只是一場理論上的空中樓閣。為了檢驗 SWE-Pruner 的工程落地可行性,研究深入剖析了其系統延遲與代碼結構維護能力。
首字節延遲(TTFT)與運算經濟學
在模型推論的生命週期中,首字節延遲(Time To First Token)是決定系統響應靈敏度的核心指標。實驗針對不同長度的輸入序列,測量了 SWE-Pruner 與多個常規生成式大模型的 TTFT 。
| 序列長度 (Tokens) | Qwen3-0.6B | Qwen3-4B | Qwen3-14B | Qwen3-32B | SWE-Pruner (0.6B) |
|---|---|---|---|---|---|
| 512 | 32.00 ms | 104.93 ms | 143.65 ms | 84.01 ms | 42.05 ms |
| 2048 | 29.64 ms | 99.10 ms | 129.97 ms | 274.22 ms | 49.05 ms |
| 8192 | 76.73 ms | 241.97 ms | 529.45 ms | 1188.67 ms | 102.00 ms |
數據展示了 SWE-Pruner 極其優越的次線性(Sublinear)延展特性。在處理高達 8192 個詞塊的龐大檔案時,SWE-Pruner 的耗時僅需 102.00 毫秒,這速度是 14B 模型的 5 倍以上,更是 32B 模型(需 1188.67 毫秒)的 11 倍之快 。從企業運算的經濟學視角切入,呼叫如 Claude 4.5 這樣的高階閉源模型,單次 API 的網路往返與運算往往耗時數秒;SWE-Pruner 區區不到 0.1 秒的「攔截檢查費」,在其創造的 23%~54% 詞塊縮減與高達 20% 的整體推論時間節省面前,其投資報酬率無疑是壓倒性的優勢 。
條件隨機場與 AST 完整性的物理關聯
除了速度,壓縮後的「代碼品質」更是決定生死存亡的關鍵。研究團隊運用 tree-sitter 工具對各種方法壓縮後的代碼進行了嚴格的抽象語法樹(AST)正確性測試 。
結果令人咋舌:依賴機率閾值的詞塊級修剪方法 LLMLingua2 與 Selective Context,其 AST 存活率僅剩淒慘的 0.29% 與 12.4% 。這解釋了為何它們在除錯任務中屢屢讓模型崩潰。然而,SWE-Pruner 在基於 Function RAG 的基礎上進行二次深度修剪後,依然維繫了高達 87.3% 的 AST 正確性 。
這種近乎奇蹟般的結構保存能力,正是源自於其架構中條件隨機場(CRF)的物理特徵。CRF 的轉移矩陣在數萬筆黃金標準資料的訓練下,深刻內化了程式語言的拓樸定律——當模型決定保留某一個核心的賦值語句時,CRF 會透過轉移機率的鏈式傳導,自動賦予該語句所屬的函式宣告行、if 判斷式以及關鍵的閉合右括號 } 極高的連帶保留權重 。正是這種「牽一髮而動全身」的結構共振設計,讓 SWE-Pruner 得以在剔除大量雜訊的同時,完美捍衛程式碼的神聖句法骨架 。
認知軌跡重塑:SWE-Bench 案例深度還原
為了將抽象的量化指標轉化為具體的認知行為變化,報告擷取了兩個極具代表性的 SWE-Bench 任務軌跡,生動展示了上下文修剪如何徹底重塑智能體的解題行為學。
案例一:從災難性溢位到精準狙擊(高影響力場景)
在處理 django__django-10554 任務時,目標是修復一個關於 Query.clone() 方法中缺失深拷貝的幽微邏輯缺陷 。
在沒有修剪機制的 Baseline 設置下,智能體陷入了嚴重的「資訊恐慌」。它瘋狂呼叫了 59 次讀取與 39 次搜尋指令,試圖用 grep 與片段式的 sed 指令在大海中撈針。這種無目標的廣度優先探索,導致歷史紀錄中塞滿了支離破碎且互不相關的代碼片段。最終,在其經歷了 164 步的痛苦掙扎後,峰值提示詞長度飆破 87,790 詞塊,總消耗超過 700 萬詞塊,系統因超過資源上限而宣告任務失敗 。
相反地,配備了 SWE-Pruner 的智能體展現了宛如資深工程師般的冷靜與俐落。它僅透過 20 次讀取與 10 次搜尋,並巧妙利用 context_focus_question 參數指示系統:「篩選出與 Query 類別中 clone 邏輯相關的部分」。藉助修剪器提供的乾淨視野,智能體迅速鎖定了核心檔案 query.py 中 if self.combinator: 的判斷分支。最終,它僅用 56 步便成功結案,總詞塊消耗驟降 83.3%(僅 1.17M tokens) 。這揭示了修剪機制不僅是節約工具,更是將「註定失敗的資源耗竭」扭轉為「成功修復」的決定性力量。
案例二:降低認知不確定性(結構性效率紅利)
在另一個任務 django__django-11740(添加外鍵依賴追蹤邏輯)中,Baseline 與 Pruner 智能體最終皆成功解題,但其內部的心智狀態卻大相逕庭 。
Baseline 智能體雖然在 42 步內完工,但在這過程中,由於其面對的是大量未經整理的原始碼,模型展現出了極高的「認知不確定性」(Cognitive Uncertainty)。它不僅反覆讀取相同檔案的不同片段,甚至還耗費了額外的步驟去建立如 /tmp/test_uuid_to_fk3.py 這樣的臨時驗證腳本,試圖透過執行副程式來確認自己對混亂上下文的理解是否正確 。
而 Pruner 智能體雖然多走了幾步(48 步),但因為它每次讀取得到的都是高度聚焦的核心邏輯,模型充滿自信地直接對 autodetector.py 進行了精準編輯,完全省略了建立防禦性驗證腳本的冗餘行為。最終,其峰值提示詞長度減少了 30.2%,整體詞塊消耗也更為精簡 。這深刻表明:給予模型更少但更純粹的資訊,能有效激發其推理自信,促成更直接且具備經濟效益的干預行為。
智能體提示詞工程與系統整合哲學
SWE-Pruner 能夠順暢運作,其背後隱藏著一套精心設計的提示詞工程(Prompt Engineering)範本。這些範本在系統底層重塑了智能體與環境對話的標準協議 。
在 Mini SWE Agent 的系統設定中,框架強制規定智能體的每次輸出必須嚴格遵守雙段式結構:首先是闡述內部推理邏輯的 THOUGHT 區塊,接著才是包含 context_focus_question 的 bash 執行區塊 。系統範本中更是清晰地定義了過濾意圖的邊界:
優秀的提問必須是自包含且具備強烈業務意圖的,例如「某個功能在代碼中是如何實作的?」;而諸如「載入函數」或「讀取 50 到 100 行」這類包含實體檔案資訊或過於模糊的短語,則被嚴格禁止 。
這種設計哲學實作了「意圖」與「操作」的完美解耦:智能體負責思考「我要找什麼邏輯」(Cognitive Chain),而底層的神經略讀器則負責執行「在實體檔案中將這段邏輯完整無損地抽離出來」(Execution Chain)。同時,為了確保資料集訓練出的略讀器具備高度的實戰價值,團隊在品質評估提示詞(Quality Evaluation Prompt)中明確告誡裁判模型:評估修剪成敗的最高指導原則在於「語義與結構的留存」,即使移除了大量代碼,只要剩餘的邏輯具備獨立可讀性與括號匹配性,即應賦予高分 。這些隱含在提示詞深處的工程巧思,共同構建了 SWE-Pruner 無懈可擊的運作閉環。
系統局限性探討與未來研究的戰略方向
儘管 SWE-Pruner 展現了顛覆性的效能躍升,本報告秉持客觀嚴謹之學術立場,深入剖析該系統目前面臨的理論局限與未來優化空間:
首先是跨生態系統的語言泛化挑戰。當前的實作與大規模實證測試,主要集中於 Python 語言構建的開源專案。雖然基於 CRF 的行級修剪機制在數學原理上並不依賴特定語言的保留字或語法樹結構,但若要全面平移至具有極度複雜泛型(Generics)與巨集(Macros)展開機制的強型別語言(如 C++ 或 Rust),神經網絡對底層記憶體管理語義的感知能力仍需透過擴充多語種訓練語料庫來進一步鍛鍊 。
其次是極致低延遲場景的微觀開銷。在非同步除錯或代理後台運作中,100 毫秒的處理延遲微不足道;但若將 SWE-Pruner 直接佈署於開發者整合開發環境(IDE)的實時即打即補全(Type-and-complete)場景中,這微小的延遲仍可能造成使用者的感知頓挫。未來的研究可透過深度的知識蒸餾(Knowledge Distillation)技術,或引入基於信賴度的提早退出(Early-exit)動態推理網路,將 0.6B 的參數規模進一步極致壓縮至 0.1B 等級 。
最後,是與時間序列維度壓縮技術的終極融合。SWE-Pruner 作為一個中介層,其核心任務是解決「空間維度」的資訊爆炸,即單次讀取龐大實體檔案的雜訊過濾。然而,這項技術與專注於「時間維度」壓縮(即折疊智能體過去冗長的思考軌跡)的框架(如 AgentFold 等)並無衝突,反而處於完美的正交互補關係。未來的終極架構,必然是一個融合了「空間精剪」與「時間折疊」的雙核驅動系統,屆時,LLM 程式碼智能體將徹底擺脫記憶容量的物理桎梏,邁向真正的全知與自治 。
總結
本分析報告對 SWE-Pruner 框架進行了全方位、深層次的技術解構與機制探討。在解決大型語言模型處理軟體工程任務時面臨的「上下文之牆」挑戰中,SWE-Pruner 以無可辯駁的數據與嚴密的數學邏輯證明了一個核心真理:單純依賴擴展基底模型的上下文視窗(Context Window),不僅是不具經濟效益的粗暴做法,更是放任認知雜訊氾濫的錯誤方向 。
真正的破局之道,在於賦予智能體如同人類資深開發者般,具備強烈「目標導向」與「選擇性略讀」的過濾直覺。透過巧妙地將 0.6B 輕量級特徵融合神經網絡、基於條件隨機場(CRF)的行級結構感知算法,以及與現有開發工具鏈無縫接軌的意圖提示機制相結合,SWE-Pruner 成功地在複雜多變的軟體庫中殺出一條血路 。
它不僅在極端測試中為模型削減了高達 54% 的 API 計費詞塊開銷,顯著遏制了無效探勘帶來的輪數虛耗,更在極度嚴苛的壓縮壓力下,完美捍衛了程式語言神聖不可侵犯的語法結構骨架 。SWE-Pruner 的誕生,不僅宣告了早期靜態、盲目且破壞性的詞塊級上下文壓縮時代的全面終結,更為未來打造具備極高經濟效益、認知專注力與結構嚴謹性的次世代自主軟體開發智能體,樹立了一座難以逾越的工程與理論標竿。