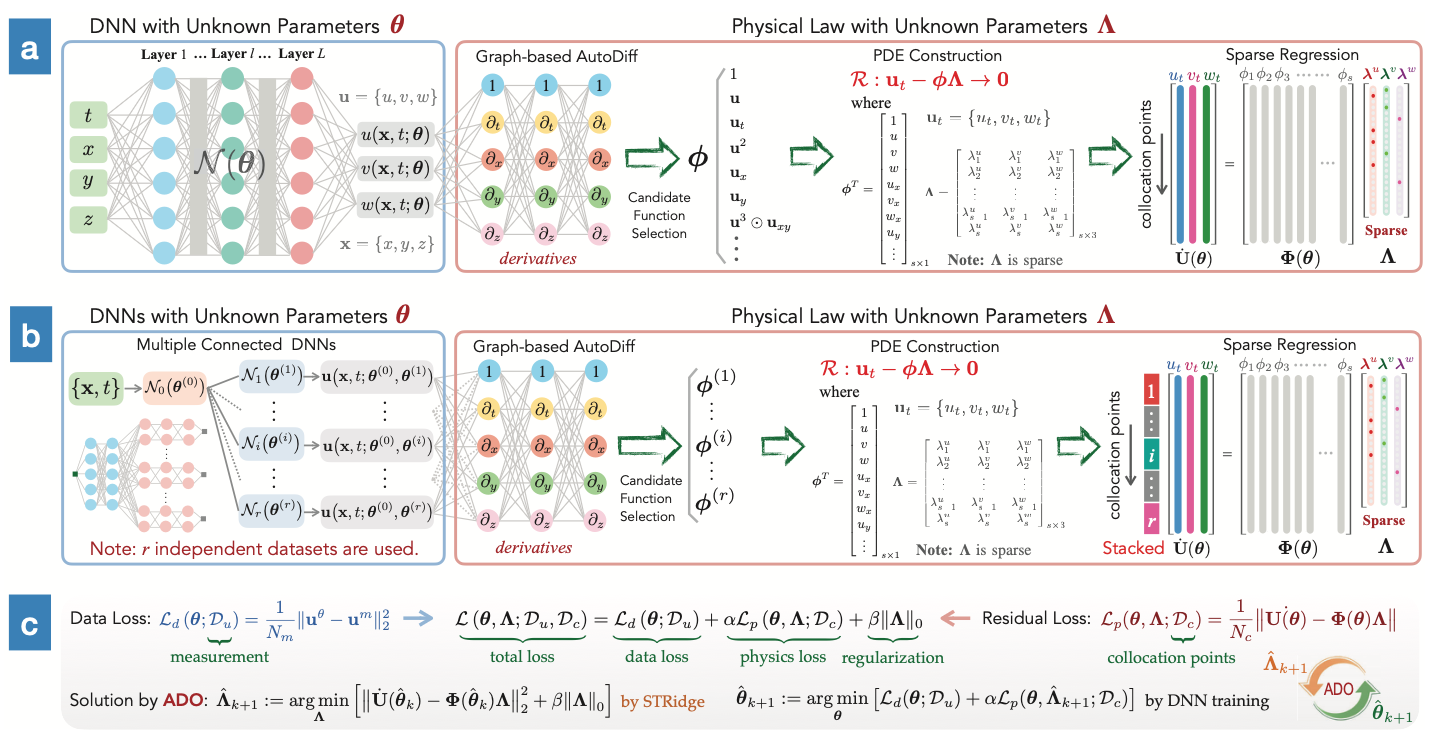
TriAttention:程式碼與推理智能體之三角函數自適應上下文修剪機制與理論深度分析報告
2026年5月11日
隨著人工智慧在軟體工程與複雜邏輯運算領域的快速演進,大語言模型(Large Language Models, LLMs)的應用範疇已經從早期的單純文本補全(Code Completion),跨越至具備自主決策與長鏈條推理能力的代理系統(Autonomous Agents)
2026年5月11日
隨著人工智慧在軟體工程與複雜邏輯運算領域的快速演進,大語言模型(Large Language Models, LLMs)的應用範疇已經從早期的單純文本補全(Code Completion),跨越至具備自主決策與長鏈條推理能力的代理系統(Autonomous Agents)
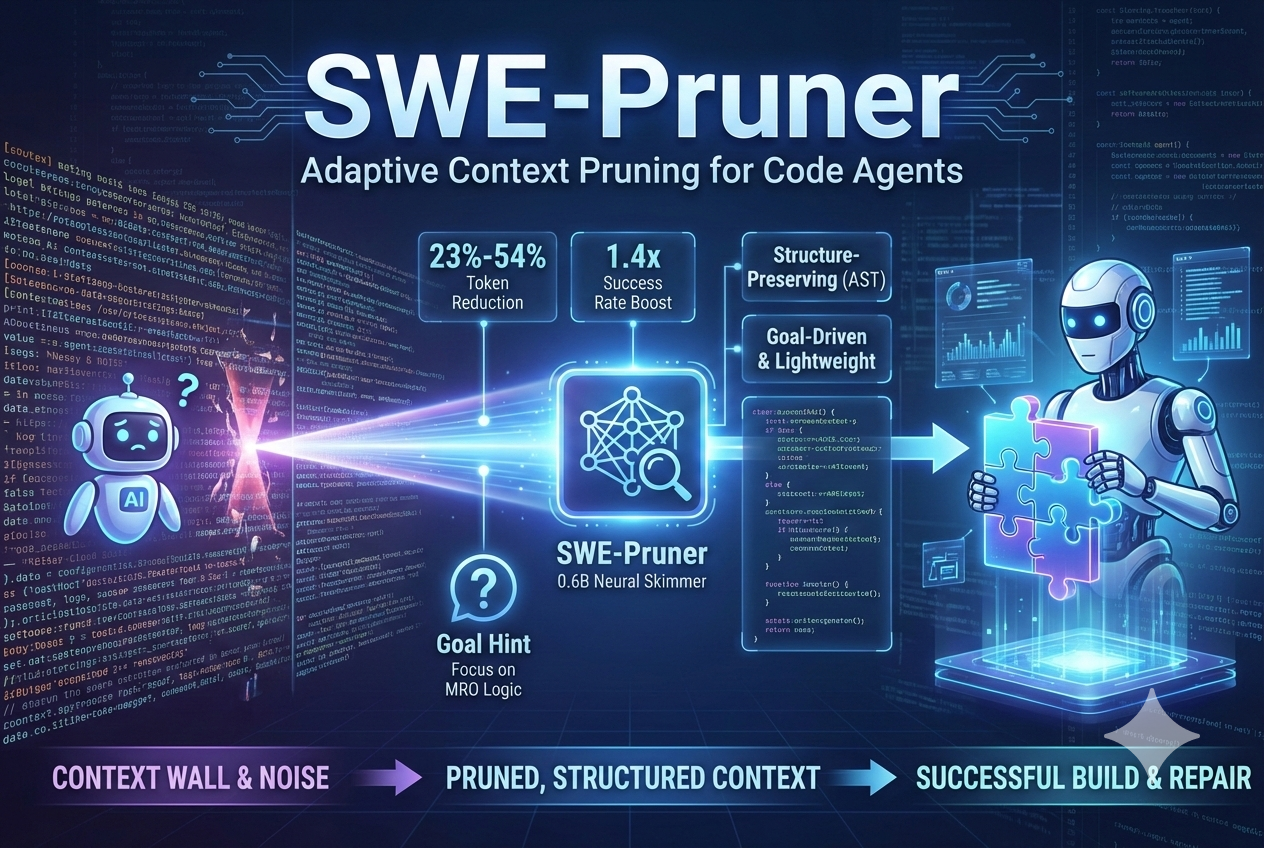
2026年2月25日
在當代軟體工程的演進歷程中,大型語言模型(Large Language Models, LLMs)的應用已經跨越了單純的程式碼片段補全與靜態語義分析,正式邁入能夠自主導航龐大程式碼庫
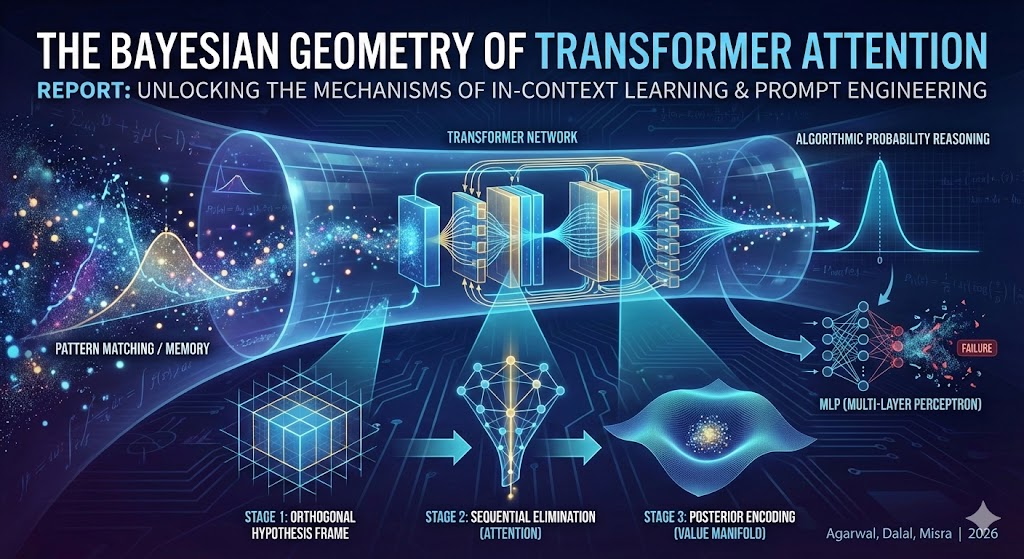
2026年1月15日
Naman Agarwal等人2026年開創性研究證實Transformer透過注意力機制精確實現貝葉斯推理,揭示其上下文學習的幾何本質並為提示工程奠定理論基礎。
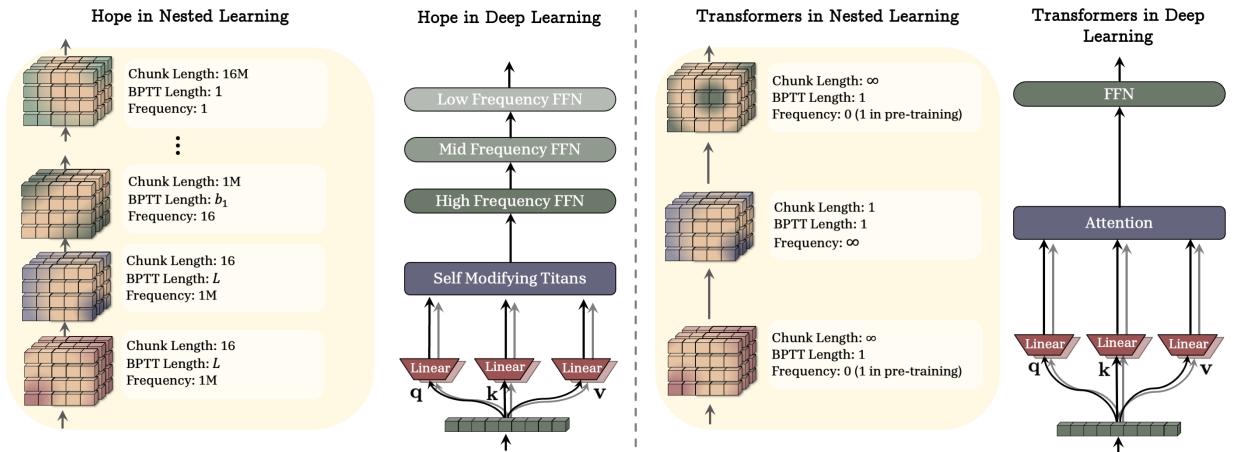
2025年12月22日
提出了 嵌套學習 這一新的學習典範,將機器學習模型表示為一組嵌套的、多層次的優化問題,每一層都有自己的「上下文流」。從 NL 的角度看,現有深度學習方法通過壓縮自身的上下文流來從數據中學習,而大型模型中的上下文學習自然湧現。NL 提出了一種哲學思想,即設計具有更多「層次」、更富表達力的學習演算法,從而實現更高階的上下文學習,並可能解鎖有效的持續學習能力。